Tác giả: V.Đ.Thuận
Bài báo này trình bày chi tiết về kiến trúc Transformer – nền tảng đã tạo nên bước ngoặt trong lĩnh vực Trí tuệ nhân tạo (AI), đặc biệt là các mô hình tạo sinh (Generative AI – GenAI). Khác với các mạng hồi quy RNN (Recurrent Neural Networks) hay tích chập CNN (Convolutional Neural Network), Transformer sử dụng cơ chế tự chú ý (Self-Attention) để mô hình hóa mối quan hệ toàn cục giữa các phần tử dữ liệu, giúp cải thiện đáng kể hiệu năng và khả năng mở rộng. Bài viết phân tích cấu trúc, nguyên lý hoạt động, khả năng mở rộng và các ứng dụng nổi bật của Transformer.
Từ khóa
Transformer, Self-Attention, GenAI, Học sâu, Deep Learning, Mạng nơ-ron, Neural Network.
Từ viết tắt và Thuật ngữ
| Từ viết tắt | Tiếng Anh | Tiếng Việt | Thuật ngữ/Giải thích |
|---|---|---|---|
| AI | Artificial Intelligence | Trí tuệ nhân tạo | Ngành khoa học máy tính nghiên cứu việc mô phỏng trí thông minh của con người bằng máy tính, bao gồm học máy, xử lý ngôn ngữ tự nhiên, thị giác máy tính và ra quyết định tự động. |
| GenAI | Generative Artificial Intelligence | AI tạo sinh | Nhánh của AI tập trung vào việc sinh dữ liệu mới (văn bản, hình ảnh, mã, âm thanh…) dựa trên mô hình học sâu (Deep Learning). Các ví dụ nổi bật: ChatGPT, Midjourney, DALL·E. |
| CNN | Convolutional Neural Network | Mạng nơ-ron tích chập | Mạng nơ-ron chuyên dùng trong thị giác máy tính, mô phỏng cách con người nhận biết hình ảnh bằng cách trích xuất đặc trưng (features) thông qua các lớp tích chập (convolution layers). |
| Self-Attention | Self-Attention Mechanism | Cơ chế tự chú ý | Cơ chế cốt lõi của Transformer giúp mô hình xác định mức độ liên quan giữa các phần tử trong chuỗi dữ liệu, cho phép học ngữ cảnh toàn cục thay vì tuần tự. |
| LSTM | Long Short-Term Memory | Bộ nhớ ngắn–dài hạn | Biến thể của RNN giúp khắc phục vấn đề mất thông tin dài hạn bằng cách sử dụng các cổng (gates) điều khiển dòng chảy dữ liệu, cho phép ghi nhớ và quên chọn lọc. |
| GRU | Gated Recurrent Unit | Đơn vị hồi quy có cổng | Phiên bản rút gọn của LSTM, có ít tham số hơn, sử dụng hai cổng (reset, update) để điều chỉnh thông tin, giúp huấn luyện nhanh hơn nhưng vẫn hiệu quả cho dữ liệu chuỗi. |
| NLP | Natural Language Processing | Xử lý ngôn ngữ tự nhiên | Ngành con của AI, tập trung vào việc cho máy tính hiểu và sinh ngôn ngữ tự nhiên của con người, bao gồm dịch máy, nhận diện thực thể, tóm tắt và sinh văn bản. |
| BERT | Bidirectional Encoder Representations from Transformers | Biểu diễn hai chiều từ Transformer | Mô hình do Google AI (2018) phát triển, dựa trên Encoder của Transformer, cho phép hiểu ngữ cảnh hai chiều (trái–phải, phải–trái) để phục vụ các tác vụ hiểu ngôn ngữ (hiểu nghĩa, trích xuất, phân loại). |
| GPT | Generative Pre-trained Transformer | Transformer sinh tiền huấn luyện | Mô hình do OpenAI (2018–nay) phát triển, dựa trên Decoder của Transformer, dùng cho tác vụ sinh nội dung tự động (văn bản, code, hội thoại). Là nền tảng của ChatGPT, GPT-4, v.v. |
| ViT | Vision Transformer | Transformer thị giác | Phiên bản của Transformer áp dụng cho xử lý ảnh. Ảnh được chia thành các “miếng” (patches) và mô hình học mối quan hệ giữa chúng bằng Self-Attention thay vì CNN. |
| LLM | Large Language Model | Mô hình ngôn ngữ lớn | Mô hình học sâu được huấn luyện trên khối lượng văn bản khổng lồ nhằm học xác suất phân phối ngôn ngữ. LLM là nền tảng của các hệ thống GenAI (GPT, Claude, Gemini, Llama, Mistral…). |
I. Giới thiệu
Trước năm 2017, các mô hình xử lý chuỗi như RNN, LSTM (Long Short-Term Memory) hay GRU (Gated Recurrent Unit) là công cụ chủ đạo trong xử lý ngôn ngữ tự nhiên (NLP). Tuy nhiên, chúng gặp hạn chế trong việc nắm bắt ngữ cảnh dài hạn, không thể song song hóa và tiêu tốn nhiều tài nguyên huấn luyện. Sự ra đời của Transformer (Vaswani et al., 2017) đã thay đổi hoàn toàn hướng phát triển của AI bằng việc loại bỏ hoàn toàn tính tuần tự và thay thế bằng cơ chế chú ý (Attention).
II. Cơ sở lý thuyết và các nghiên cứu liên quan
Khái niệm Attention được giới thiệu lần đầu trong dịch máy thần kinh (Bahdanau et al., 2014), cho phép mô hình tập trung vào các phần quan trọng của đầu vào. Transformer mở rộng ý tưởng này thành cơ chế Self-Attention, nơi mỗi phần tử trong chuỗi có thể học mối quan hệ với toàn bộ phần tử khác. Kể từ đó, nhiều biến thể như BERT, GPT, Vision Transformer (ViT) và các mô hình đa phương thức đã chứng minh sức mạnh vượt trội của kiến trúc này.
III. Kiến trúc Transformer
1. Thành phần chính
Transformer bao gồm hai thành phần chính: Bộ mã hóa (Encoder) và Bộ giải mã (Decoder). Bộ mã hóa có nhiệm vụ trích xuất đặc trưng ngữ cảnh từ đầu vào, trong khi bộ giải mã sử dụng thông tin này để sinh đầu ra.
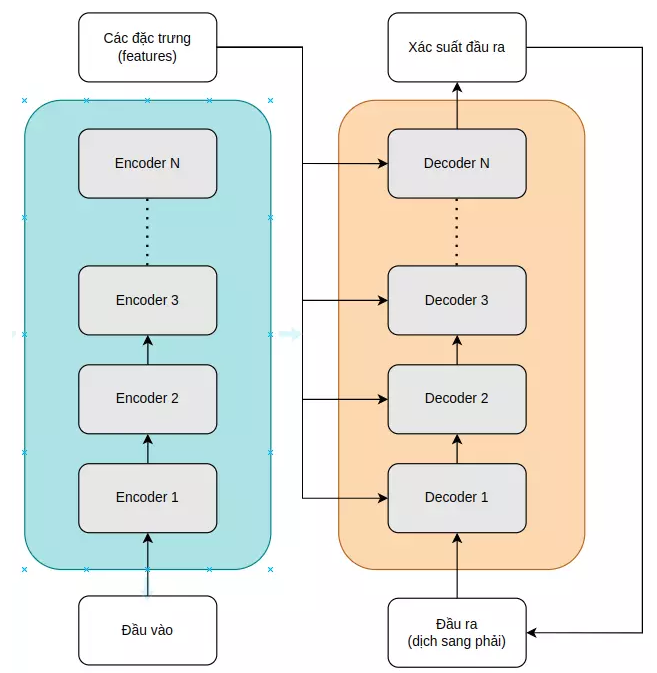
Hình 1. Sơ đồ tổng quan kiến trúc Transformer.
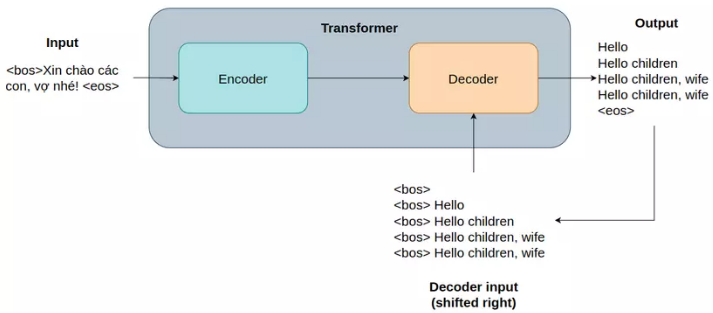
Hình 2. Mô tả cách hoạt động của Transformer
2. Sự khác biệt giữa Transformer và các mạng nơ-ron khác
Mô hình Transformer đánh dấu một bước chuyển lớn so với các kiến trúc mạng nơ-ron trước đây như RNN (Recurrent Neural Networks – mạng nơ-ron hồi tiếp) và CNN (Convolutional Neural Networks – mạng nơ-ron tích chập).
- RNN: xử lý đầu vào theo trình tự, phù hợp với các nhiệm vụ như nhận dạng giọng nói và xử lý ngôn ngữ tự nhiên thời kỳ đầu. Tuy nhiên, chúng gặp khó khăn trong việc ghi nhớ ngữ cảnh dài hạn và không dễ mở rộng quy mô.
- CNN: chủ yếu được sử dụng trong thị giác máy tính, giúp vận hành các tác vụ như nhận diện khuôn mặt để xác thực trên điện thoại thông minh.
Không giống như RNN và CNN, Transformer phân tích toàn bộ chuỗi đầu vào cùng lúc nhờ cơ chế tự chú ý (self-attention), cho phép nhận diện các mối quan hệ phức tạp trong dữ liệu một cách hiệu quả hơn. Điều này khiến Transformer đặc biệt phù hợp với các ứng dụng doanh nghiệp như phân tích hợp đồng, chatbot AI và dịch thuật đa ngôn ngữ. Tuy nhiên, kích thước lớn và nhu cầu tài nguyên cao của mô hình cũng có thể gây thách thức về khả năng mở rộng trong môi trường thực tế.
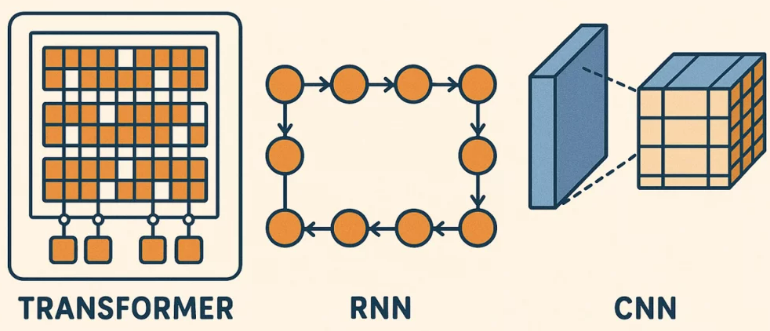
Hình 3. Minh họa cơ chế xử lý của Transformer, RNN, CNN
IV. Cơ chế Tự chú ý (Self-Attention)
Self-Attention là thành phần cốt lõi giúp Transformer nắm bắt mối liên hệ giữa các phần tử trong chuỗi. Mỗi phần tử được biểu diễn bằng ba véc-tơ: Query (Q), Key (K) và Value (V). Công thức tính chú ý được biểu diễn như sau:
Attention(Q, K, V) = softmaxQKTdkV
Attention(Q, K, V) = softmax(
QKT/√ dk
) V
Nhờ cơ chế này, Transformer có thể học được các quan hệ ngữ nghĩa dài hạn và xử lý toàn bộ chuỗi cùng lúc. Multi-Head Attention mở rộng khái niệm này bằng cách cho phép mô hình học song song nhiều loại quan hệ ngữ nghĩa khác nhau.

Hình 4. Mô hình kiến trúc của Transformer
Trong thế giới của trí tuệ nhân tạo và học máy, transformer đã trở thành một khái niệm không thể thiếu trong lĩnh vực xử lý ngôn ngữ tự nhiên (NLP)
V. Ứng dụng và Kết quả
Transformer hiện được ứng dụng rộng rãi trong các lĩnh vực:
– Xử lý ngôn ngữ tự nhiên: dịch máy, tóm tắt văn bản, hỏi đáp.
– Trí tuệ thị giác: Vision Transformer (ViT) thay thế CNN.
– Hệ thống sinh mã nguồn, sinh ảnh và video.
– Ứng dụng đa phương thức như CLIP, Gemini, Flamingo.
| Đặc điểm | RNN | LSTM | GRU | Transformer |
|---|---|---|---|---|
| Xử lý tuần tự | Có | Có | Có | Không (song song) |
| Học ngữ cảnh dài hạn | Kém | Tốt | Tốt | Rất tốt |
| Khả năng song song hóa | Thấp | Thấp | Trung bình | Rất cao (GPU-friendly) |
| Chi phí tính toán | Thấp | Cao | Trung bình | Cao nhưng hiệu quả |
| Ứng dụng chính | NLP cổ điển | Dịch máy, giọng nói | NLP cơ bản | GenAI, LLM, Vision AI |
Bảng 1. So sánh tổng hợp giữa RNN, LSTM, GRU và Transformer
VI. Thảo luận
Mặc dù Transformer mang lại bước tiến vượt bậc, nó cũng đối mặt với thách thức về chi phí huấn luyện và độ phức tạp tính toán O(n²). Các hướng nghiên cứu hiện nay tập trung vào việc tối ưu hóa như Linformer, Performer, Sparse Attention và Mixture-of-Experts (MoE). Những cải tiến này giúp giảm chi phí nhưng vẫn duy trì hiệu năng mô hình.
VII. Kết luận
Transformer là cột mốc quan trọng trong lịch sử AI, thay đổi cách máy học biểu diễn thông tin. Nhờ khả năng học ngữ cảnh toàn cục, song song hóa mạnh mẽ và khả năng mở rộng, Transformer trở thành nền tảng của GenAI hiện đại. Trong tương lai, các phiên bản Transformer hiệu quả hơn sẽ tiếp tục định hình kỷ nguyên AI thế hệ mới.
Tài liệu tham khảo
- Vaswani et al., “Attention Is All You Need,” NIPS, 2017.
- Devlin et al., “BERT: Pre-training of Deep Bidirectional Transformers,” NAACL, 2018.
- Dosovitskiy et al., “An Image is Worth 16×16 Words: Vision Transformer,” ICLR, 2021.
- Tay et al., “Synthesizer: Rethinking Self-Attention,” ICML, 2020.
- Kaplan et al., “Scaling Laws for Neural Language Models,” arXiv, 2020.
- Khan et al., “Transformers in Vision: A Survey,” ACM Comput. Surveys, 2022.
- Bommasani et al., “Foundation Models,” Stanford CRFM, 2021.


Không có nhận xét nào:
Đăng nhận xét